
Methods of Preparing Data for Machine Learning Models
In any machine learning project, data preparation is essential since it directly affects the accuracy and performance of your model. But it’s frequently disregarded or misinterpreted.
You will discover what data preparation is and why it is necessary for effective machine learning results in this guide. Additionally, you’ll discover a few widespread myths that can impede your advancement. Most importantly, you’ll receive a thorough, step-by-step manual that will help you efficiently handle the data preparation procedure.
Step 1: Collecting data
The first step in data preparation for machine learning is collecting the data you’ll need for your model.
The sources of this data can vary widely depending on your project’s requirements. You might pull data from databases, APIs, spreadsheets, or even scrape it from websites. Some projects may also require real-time data streams.
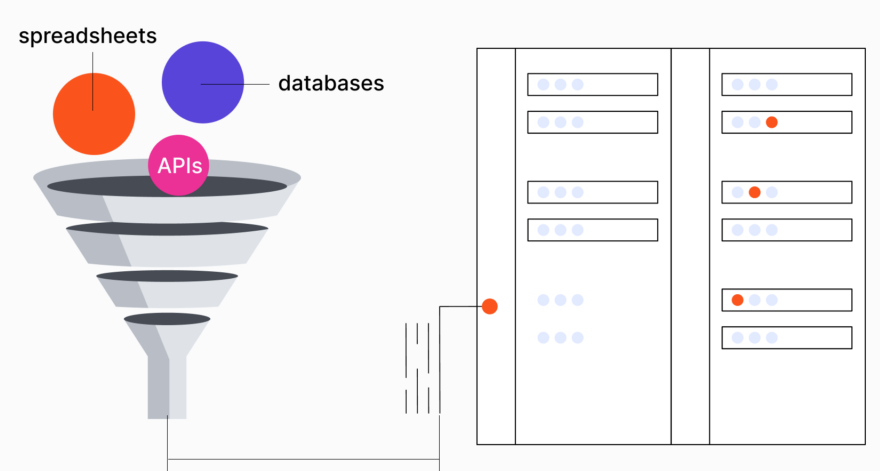
It’s important to ensure the data you collect is relevant to the problem you’re trying to solve. Irrelevant or low-quality data can lead to poor model performance, so be selective and focused in your data collection efforts.
Step 2: Cleaning data
Once you’ve collected your data, the next step is to clean it. Here you’ll need to identify and handle missing values, outliers, and inconsistencies in the dataset.
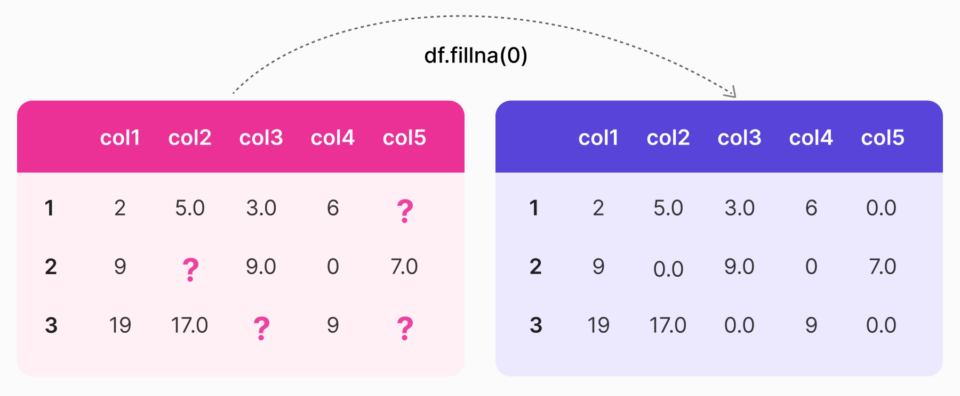
The next step to take to prepare data for machine learning is to clean it. Cleaning data involves finding and correcting errors, inconsistencies, and missing values.
Step 3: Data transformation
Transforming your data is crucial because how you prepare it will directly impact how well your model can learn from it.
Data transformation is the process of converting your cleaned data into a format suitable for machine learning algorithms. This often involves feature scaling and encoding, among other techniques.
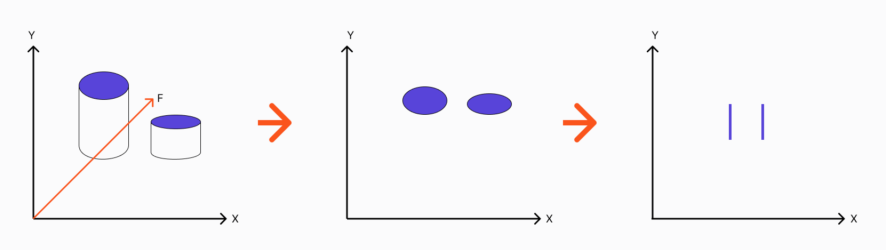
During the data transformation stage, you convert raw data into a format suitable for machine learning algorithms. That, in turn, ensures higher algorithmic performance and accuracy.
Step 4: Data reduction
Simplifying your data helps your machine learning model spot patterns more easily, offering quick and accurate marketing information for timely decisions.
Data reduction is the process of simplifying your data without losing its essence. This is particularly useful in marketing, where you often deal with large datasets that can be cumbersome to analyze.
Data reduction techniques can make your datasets more manageable and speed up your machine-learning algorithms without sacrificing model performance.
Step 5: Data splitting
The last step in preparing your data for machine learning is splitting it into different sets: training, validation, and test sets.
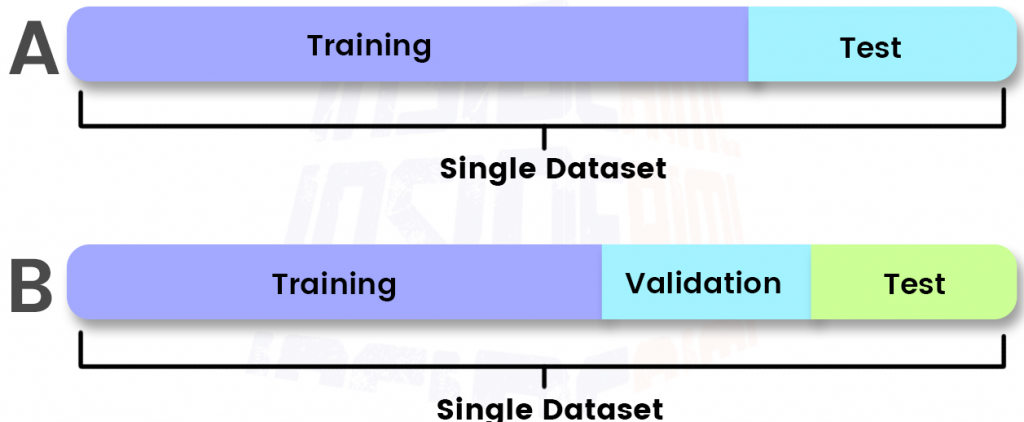
Correctly splitting your data ensures your machine learning model can generalize well to new data, making your marketing data more reliable and actionable.
The next step in the process of preparing data for machine learning involves dividing all gathered data into subsets — the process known as data splitting. Typically, the data is broken down into a training, validation, and testing dataset.
Let’s go!
Data preparation is essential for effective machine learning models. It involves crucial steps like cleaning, transforming, and splitting your data. Properly preparing data for machine learning is essential to developing accurate and reliable machine learning solutions. We understand the challenges of data preparation and the importance of having a quality dataset for a successful machine learning process.
What is AI ?
Artificial intelligence, in its broadest sense, is intelligence exhibited by machines, particularly computer systems, as opposed to the natural intelligence of living beings.
A.I. is Relevance to Us
- What is AI?
- How does ChatGPT work?
- What are the pros and cons of using AI?
- Tips and tricks on how to get the most out of AI.

We need to Understand how to Handle Dataset?
- Training dataset
- Validation dataset
- Testing dataset
Generative AI + Oracle APEX for (RAD) Rapid Application Development
AI systems that use generative modeling and large language models (LLMs) are developing quickly. Peer programming—where a peer is an expert in programming languages, analytics, data modeling, documentation, unit testing, and much more—is made possible for developers by generative AI systems. This article examines how to translate text to SQL using Oracle APEX and Large Language Models—a chore that every APEX developer must perform. The Generative AI system receives a query from the developer, either oral or written, and its job is to generate an Oracle SQL statement that “implements” the inquiry. After that, the developer could wish to test, validate, or make additional changes to the SQL query to suit their needs.

High Level Architecture
The diagram illustrates the high-level architecture of our AI Oracle Apex solution.

Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) attempts to enhance the response quality by constructing a richer prompt at inference time that incorporates a combination of context, history, and pertinent “knowledge” from an external datastore (such as an Oracle Database with vector database functionality). Where RAG is used for the APEX Assistant is depicted in the diagram.